Gluesync Automator 

Gluesync Automator is a standalone executable that provides a user-friendly web interface to run the Gluesync Bootstrapper’s create_all_entities.py script without requiring Python dependencies or command-line knowledge.
![]() This project is Open Source
This project is Open Source
Overview
The Automator packages the Bootstrapper functionality into a single executable file that launches a local web server at http://localhost:8080. It provides a graphical interface for:
-
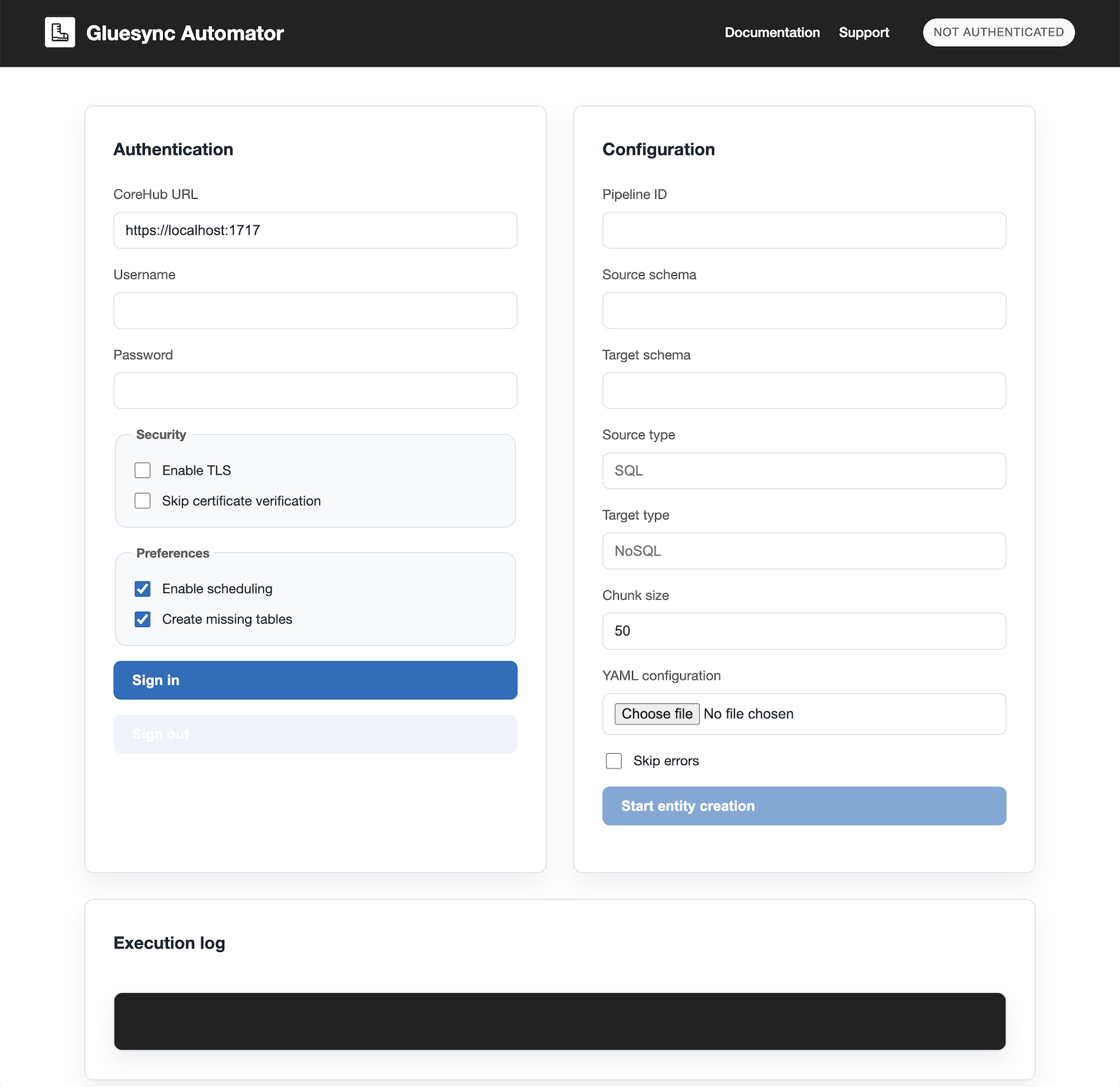
Authenticating with Gluesync Core Hub
-
Uploading YAML configuration files
-
Configuring entity creation options
-
Monitoring live logs during execution
-
Downloading logs for troubleshooting
This makes the Bootstrapper accessible to users who prefer graphical tools over command-line interfaces, while maintaining all the underlying automation capabilities.
Key features
-
Web-based interface
-
Accessible via any web browser at
localhost:8080 -
Responsive design works on desktop and mobile devices
-
Gluesync-branded interface matching documentation styling
-
-
Simplified authentication
-
Secure login to Core Hub with TLS options
-
Certificate verification controls
-
Token management and validation
-
-
Configuration management
-
Drag-and-drop YAML file uploads
-
Validation of configuration files
-
Support for all Bootstrapper YAML formats
-
-
Entity creation options
-
Toggle automatic table creation
-
Enable/disable scheduling for entities
-
Skip errors option for batch processing
-
Configurable chunk sizes for large deployments
-
-
Real-time monitoring
-
Live streaming of execution logs
-
Color-coded status indicators (idle, running, completed, failed)
-
Progress tracking for entity creation
-
-
Cross-platform support
-
Native executables for Windows, macOS, and Linux
-
No installation required - run from any directory
-
Self-contained with all dependencies bundled
-
Installation
Usage
Launching the Automator
-
Download the executable for your platform
-
Run the file (double-click on Windows/macOS, or execute in terminal on Linux)
-
The application will start a web server and open your default browser to
http://localhost:8080
|
On macOS, the Gluesync Automator To launch it the first time:
If the Open option does not appear:
After this first approval, you can open the app normally (for example by double-clicking it). |
Using the web interface
Authentication
-
Enter your Core Hub URL (e.g.,
https://localhost:1717) -
Provide your username and password
-
Optionally configure TLS settings:
-
Enable TLS for secure connections
-
Skip certificate verification if using self-signed certificates
-
-
Click "Login" to authenticate
After a successful login, the Core Hub URL, Username and Password fields become read-only so that the active session cannot be accidentally changed. To modify these values, first click Sign out and then log in again with the new settings.
Configuration upload
-
Click "Choose File" to select your YAML configuration file
-
The interface will validate the file format
-
Configure additional options:
-
Enable/disable automatic table creation
-
Enable/disable scheduling for created entities
-
Set chunk size for batch processing
-
Choose to skip errors during execution
-
Pipeline and schema selection
The Import card also lets you control which pipeline and schemas are used when running create_all_entities.py:
-
Pipeline selector
-
The Pipeline drop-down lists all available pipelines discovered from Core Hub.
-
You must select the target pipeline before starting entity creation.
-
-
Automatic schema detection from YAML
-
By default, Automator derives source and target schemas from the uploaded YAML file (for example, from the
schemassection or top-level schema keys). -
All discovered schema pairs are processed sequentially, calling
create_all_entities.pyonce per pair.
-
-
Customize source/target schemas (override YAML)
-
When the Customize source/target schemas (override YAML) checkbox is unchecked (default):
-
The Source schema and Target schema fields are hidden.
-
Automator uses only the schemas declared in the YAML file.
-
-
When the checkbox is checked:
-
The Source schema and Target schema fields become visible and editable.
-
The values entered here override the schema information in the YAML for the current run.
-
This mode is intended for advanced scenarios where you need to force a specific schema mapping.
-
-
Running entity creation
-
Click "Start" to begin the entity creation process
-
Monitor progress through the live log output
-
The status indicator will show "Running" during execution
-
Upon completion, the status will change to "Completed" or "Failed"
Log management
-
View real-time logs in the integrated terminal window
-
Logs are automatically scrolled to show the latest output
-
Download full logs for troubleshooting or audit purposes
Pipeline export and backups
Automator also provides a dedicated Export card to back up existing pipeline configurations:
-
Pipeline selector: choose a pipeline to export (same list used by the Import and Bulk operations cards).
-
Export metadata: exports the selected pipeline configuration to a single table-list-style YAML file compatible with the Bootstrapper.
-
Full backup: exports the selected pipeline to a ZIP archive containing:
-
A table-list-style YAML file named
backup_<pipelineName>_<pipelineId>.yaml. -
A pipeline-scoped
agents-config.yamlwith agent definitions and pipeline metadata. -
The UDF source files referenced by that pipeline, grouped by owning agent in folders such as
udf-<agentId>/<UDF_NAME>.java(or other supported extensions).
-
-
Export all metadata: exports all pipelines in the Core Hub and returns them as a single ZIP archive.
These exports can be used as backups or as starting points for new Bootstrapper YAML configurations.
When you use Export all metadata, the downloaded ZIP archive contains:
-
One table-list-style YAML file per pipeline (named
backup_<name>_<pipelineId>.yaml). -
A consolidated
agents-config.yamlfile with:-
agents: a list of agent definitions matching the Bootstrapper config schema (agentType, agentTag, hostCredentials, customHostCredentials, specificConfiguration). -
pipelines: metadata that records the original pipeline IDs and names, and optionally anagentslist that specifies which agents (by agentType/agentTag) belong to each pipeline.
-
-
The UDF source files referenced by any exported pipeline, grouped by owning agent in folders such as
udf-<agentId>/<UDF_NAME>.java.
For security reasons, passwords inside hostCredentials are masked when exporting:
password: ******* # original password omittedBefore importing this configuration, you must edit the exported config to replace the * placeholders with real passwords. If masked passwords are still present when you attempt an import, the Automator will reject the request and display an error explaining that the passwords must be filled in first.
The Export card also provides import helpers:
-
Import config: accepts a single config file (JSON or YAML) shaped like the Bootstrapper’s
config.json/config.yamlexample. It creates a new pipeline in the target Core Hub and binds agents according to the file, but does not create entities or start syncs. -
Validate: accepts the same ZIP file as Import All or a single-pipeline Full backup and performs a dry-run validation. It checks that the archive structure is correct,
agents-config.yamlis well formed, passwords have been replaced, and each pipeline YAML contains at least one schema pair. The detailed validation report is printed in the Automator log panel, while the UI indicates whether the validation passed or failed. -
Import All: accepts the ZIP file produced by Export all metadata (or any ZIP following the same layout, including a single-pipeline Full backup) and recreates all pipelines contained in the archive. For each pipeline, it:
-
Creates a new pipeline (adding a
(restored)suffix to the name when needed to avoid name clashes). -
Binds the appropriate agents using the information from
agents-config.yaml. -
Applies each table-list YAML to create entities, without starting any syncs.
-
Automatically compiles and registers any UDFs referenced in the YAML using the exported source files from the backup, by invoking the same helper used by the Bootstrapper (
create_user_defined_functions.py).
-
For a step-by-step guide to backing up and restoring pipelines using Automator, see Backup and restore.
Bulk operations
In addition to YAML-driven imports, Automator provides a Bulk operations card that lets you create entities directly from a source schema without preparing a YAML file first.
The Bulk operations card works as follows:
-
Pipeline
-
Drop-down listing all pipelines discovered from Core Hub (same list used by the Import and Export cards).
-
Selects the pipeline whose SOURCE agent will be used for discovery.
-
-
Source schema
-
After choosing a pipeline, Automator calls the Core Hub discovery API to list available schemas for the SOURCE agent.
-
The Source schema drop-down is populated from
/pipelines/{pipelineId}/agents/{sourceAgentId}/discovery/schemas.
-
-
Tables list
-
Once a schema is selected, Automator lists all tables discovered for that schema using
/pipelines/{pipelineId}/agents/{sourceAgentId}/discovery/tables?schema=<schema>. -
Each table appears with a checkbox; all tables are selected by default.
-
A short summary shows how many tables are available and how many are currently selected.
-
A Toggle all button lets you quickly select or deselect all tables.
-
-
Create all entities (N)
-
The primary button label reflects the number of selected tables (for example
Create all entities (12)). -
When clicked, Automator calls a dedicated backend endpoint that:
-
Resolves the SOURCE and TARGET agents for the selected pipeline.
-
Uses the same discovery logic as the Bootstrapper to build entities for only the selected tables.
-
Invokes the underlying
create_all_entities.pylogic to create entities in Core Hub.
-
-
Bulk operations are optimized for the common case where you want to import "all tables from a given schema" (or a large subset) without maintaining a full table-list YAML. For advanced scenarios that require custom filters, UDFs, or group/schedule configuration, continue to use the YAML-based import flow described above.
Configuration options
TLS configuration
-
Enable TLS: Forces HTTPS connections to the Core Hub
-
Skip Certificate Verification: Bypasses SSL certificate validation (useful for development with self-signed certificates)
Entity creation settings
-
Create missing tables: Controls whether the Bootstrapper should generate CREATE TABLE statements for target databases
-
Enable scheduling: Automatically enables scheduled execution for created entities
-
Skip errors: Continues processing even if individual entities fail to create
-
Chunk size: Number of entities to process simultaneously (affects memory usage and performance)
-
Source/Target type: Drop-down selectors that map to the Bootstrapper’s agent types:
-
RDBMS (SQL) → sends
SQLto the backend and is used for relational/RDBMS sources or targets. -
Anything else → sends
NoSQLto the backend and is valid for document databases, event streaming platforms, object storage, or any non-RDBMS target.
-
These labels are purely UX improvements; the underlying values (SQL/NoSQL) remain backward compatible with existing scripts.
Troubleshooting
Common issues
| Issue | Possible cause | Resolution |
|---|---|---|
Application won’t start |
Port 8080 is already in use |
Close other applications using port 8080, or the Automator will prompt for an alternative port |
Authentication fails |
Incorrect Core Hub URL or credentials |
Verify the Core Hub is accessible and credentials are correct |
Configuration upload fails |
Invalid YAML format |
Validate your YAML file against the Bootstrapper schema |
Entity creation errors |
Network connectivity or Core Hub API issues |
Check Core Hub logs and network connectivity |
Slow performance |
Large chunk sizes or many entities |
Reduce chunk size or process entities in smaller batches |
Best practices
-
Store configuration files in version control alongside your infrastructure code
-
Test configurations in a development environment before production deployment
-
Keep executables updated to the latest version for security and feature improvements
-
Use consistent naming conventions for pipelines, entities, and schemas
-
Document your configuration choices for team knowledge sharing
-
Monitor Core Hub and Automator logs regularly for early issue detection
The Automator header displays the currently running version (for example, Automator v1.0.41). On startup it also performs a best-effort online check against the MOLO17 Backoffice API:
-
If a newer GA version is available, the header shows:
Automator vX.Y.Z – New version available: vA.B.C. -
A short inline changelog for the latest version is rendered below the header, together with a direct download link to https://molo17.com/gluesync-automator/.
-
If the remote services are not reachable, the UI silently falls back to showing the local version only and logs errors to the browser console for diagnostics.
Release notes
1.0.7
Released: December 10, 2025
-
Ability to export UDFs;
-
Ability to perform bulk operations such as importing all tables from a given schema;
-
Support for Bootstrapper 2.3.5;
1.0.6
Released: December 8, 2025
-
Support for Bootstrapper 2.3.4;
-
Import & export pipeline configuration (incl. pipeline, agents, entities, and tables);
1.0.50
Released: December 6, 2025
-
Added support for Bootstrapper 2.3.2;
-
UI improvements;
-
Added support for updates checking;
1.0.41
Released: December 5, 2025
-
Added support for Bootstrapper 2.3.1;
-
Added support for pipeline export (also in bulk);
1.0.0
Released: November 2, 2025
-
Initial release of Gluesync Automator
-
Web-based UI for Bootstrapper functionality
-
Cross-platform executables (Windows, macOS, Linux)
-
Live log streaming and monitoring
-
Drag-and-drop configuration uploads
-
TLS and authentication options
-
Responsive design with Gluesync branding