Parquet Files Support
Overview
Gluesync supports storing replicated data in Apache Parquet file format at the target data store level, providing enhanced performance, compression, and compatibility with analytics tools. This file format comes by default on the support agents and joins the previous support for JSON files stored in a folder-to-table manner.
Users can select the data storage format on a per-entity basis. Parquet is the default format, offering significant advantages over JSON for large-scale data processing.
| Parquet support is designed for scenarios where file-based storage in object stores is preferred over traditional database tables. |
Supported data stores
Gluesync supports Parquet file storage in the following data stores:
-
AWS S3 (and any S3-compatible storage)
-
Google Cloud Storage
-
Azure Data Lake Gen 2
How it works
When Parquet is selected as the storage format:
-
The Agent leverages Apache Arrow to perform batched data processing and compression to target Parquet files.
-
Incremental data is stored in Parquet files, with each file containing a batch of changes.
-
Batch of changes can be grouped by highering the agent’s polling interval.
-
This buffering mechanism optimizes network usage and file sizes for better performance. In the following sections, the snapshot and CDC implementation details are described.
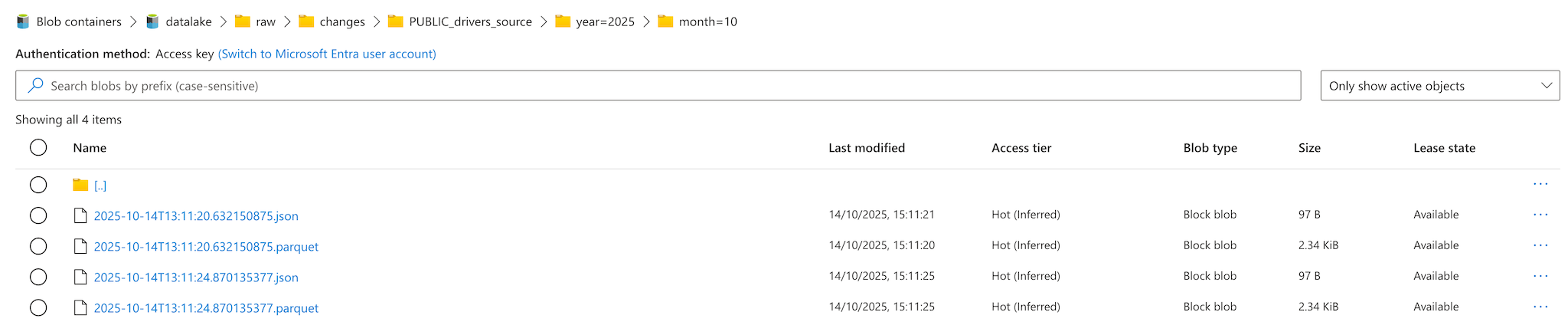
Here below an example of the folder structure created by Gluesync when Parquet is selected as the storage format:
Snapshot implementation
Snapshot operations store data in a structured folder hierarchy with the following naming convention:
/bucket_name/raw/snapshots/entity_name/year=2025/month=09/snapshot.parquet
entity_name is the name of the entity being replicated, this is configured in the Core Hub from the Objects browser.
|
File size optimization
For further optimization, files are compressed based on a buffer of batched data cached in an Avro file with a maximum size of 250 MB. This file size is configurable through the target agent configuration.
CDC implementation
Change Data Capture (CDC) operations efficiently handle inserts, updates, and deletes events in Parquet format.
Each change is stored in a single file that includes an additional column named operation which contains a single uppercase character indicating the type of operation performed:
-
I Insert
-
U Update
-
D Delete
Inserts
New rows are appended to batch files, creating multiple files per batch for optimal parallel processing.
Metadata
Each Parquet file includes a sidecar manifest file (JSON) containing:
-
Timestamp of the snapshot
-
Row count
-
Operation (Insert, Update, Delete)
-
Schema version
Configuration
-
Parquet file format are selected as default file compression in the Core Hub entity configuration.
-
Adjust polling intervals as needed (default: 100 milliseconds, consider to increase it to decrease the number of files).
Best practices
-
Use the metadata sidecar files for data lineage and validation.
-
Implement downstream merge logic for handling updates and deletes in analytics workloads.
-
Test with sample data to validate compression ratios and read performance.
Limitations and considerations
-
Parquet files are immutable; changes require new file versions.
-
Network bandwidth may impact upload performance for large batches.
Troubleshooting
-
File size issues: Adjust polling intervals or batch sizes.
-
Read performance: Verify file sizes and compression settings.
See also
-
Snapshot Tasks — Configure snapshot tasks.
-
User Defined Functions — Transform data during replication.