Fields Editor
Overview
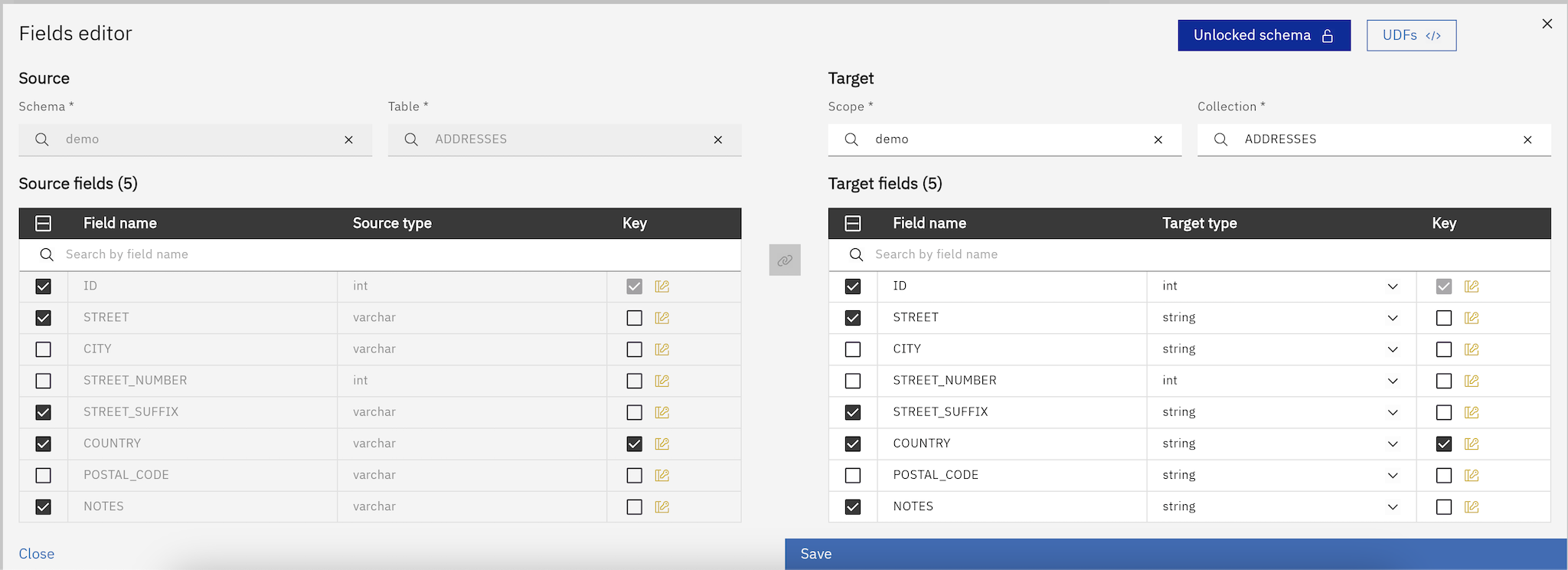
The Fields Editor, accessible from the Objects Browser, lets you review and control the list of fields (columns) for both source and target tables involved in a replication task. From here you decide what gets replicated, how it’s mapped, and how to handle keys, data type differences, and schema customization.
Key capabilities
-
Toggle fields on/off to include or exclude them from replication.
-
Define or adjust unique row identifiers when a physical primary key is not available or not discovered. See Logical Keys.
-
Detect, review, and fix data type mismatches with clear warnings and errors.
-
Rename target fields to match desired naming conventions or downstream requirements.
-
Select a different target schema and/or target table when needed.
-
Unlock the schema to add/remove target fields and overcome type-casting limitations. See Unlock Schema.
-
Attach a UDF to implement transformations and resolve non-trivial casting or mapping logic. See User Defined Functions.
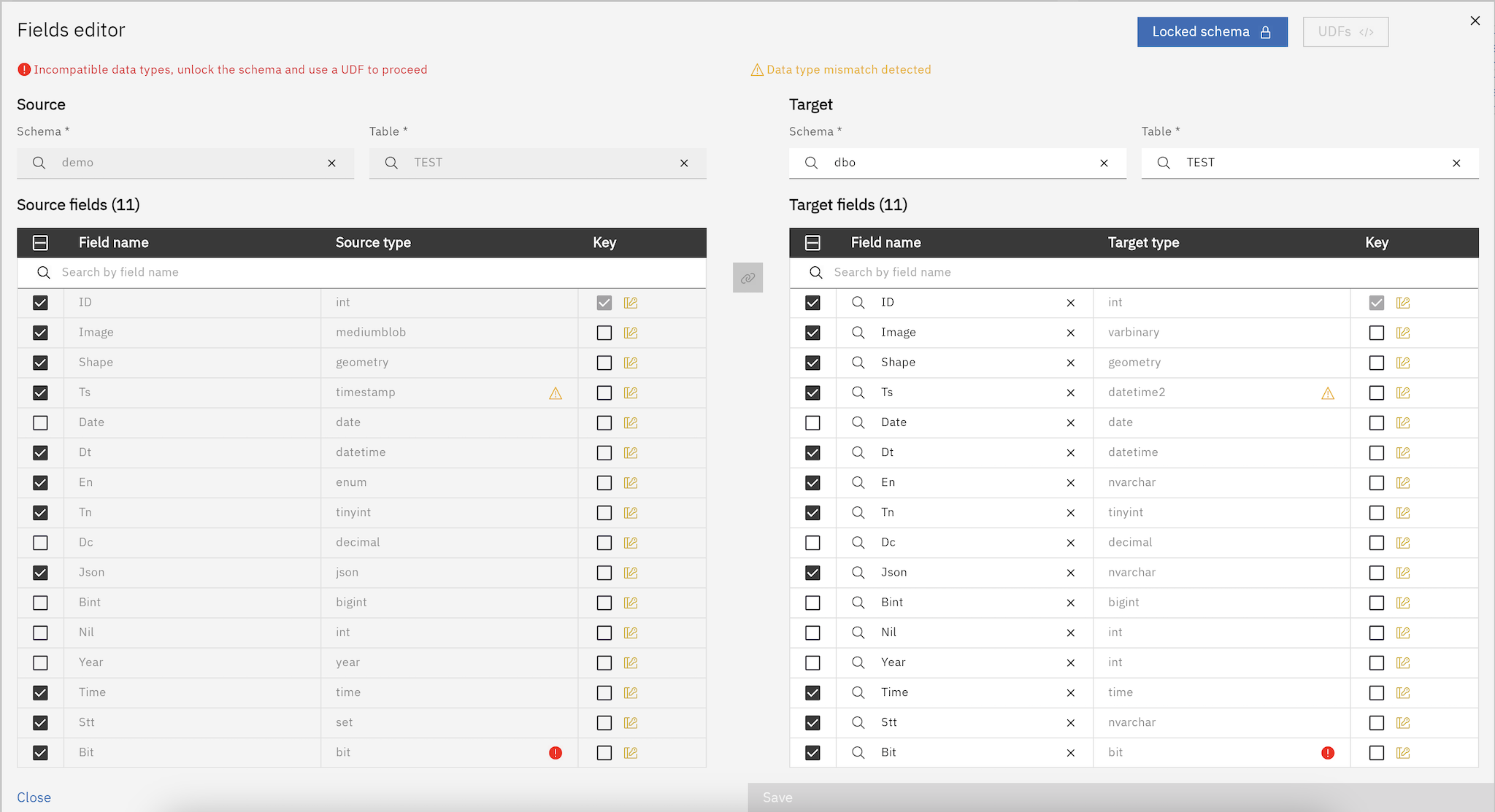
Validation: warnings and errors
The Fields Editor continuously validates your configuration and highlights issues:
-
Warning: data types are from the same family (e.g., integer to bigint) and a cast is likely safe.
-
Error: the engine cannot infer a safe cast automatically (e.g., string mapped to date). These must be addressed before deployment.
To resolve errors where automatic casting is not possible, implement the conversion in a UDF and/or unlock the schema to adjust the target type as needed:
-
Write a UDF to parse/normalize the source value into the correct target type. See UDFs.
-
If the target definition is too strict, unlock the schema to change the target column type or add helper fields.
Usage steps
-
Open the replication task in the Objects Browser and navigate to the Fields tab.
-
Review the source and target field lists.
-
Toggle/untoggle fields you want to include or exclude from replication.
-
If no physical primary key is detected or suitable, define logical keys. See Logical Keys.
-
Address validations:
-
Fix warnings as needed (for example, confirm that an implicit cast is acceptable).
-
Resolve errors by adjusting target types (unlock schema) and/or adding a UDF for custom casting.
-
-
Rename target fields where necessary to match naming standards or downstream contracts.
-
If required, select a different target schema or target table to match your deployment design.
-
Save your changes.
Editing schema and mapping
-
Use the Fields Editor to review how source columns map to target columns.
-
When deviating from a 1:1 mapping, consider unlocking the schema to add derived or technical fields (e.g.,
source_table) or to drop unneeded fields. -
Keep transformation logic in UDFs minimal and efficient; use them to parse, concatenate, normalize, and validate values.
Handling data type mismatches
-
Family-compatible casts (e.g., numeric widening) appear as warnings; confirm they match your expectations.
-
Incompatible casts (e.g.,
stringtodate) are flagged as errors; create a UDF to parse/convert and optionally unlock the schema to refine target data types. -
Test your UDF conversions on examples representative of real data (including edge cases and nulls).
Best practices
-
Prefer explicit logical keys when physical PKs are missing or unsuitable.
-
Keep naming consistent: use clear, descriptive target field names and document any renames.
-
Validate all warnings and clear errors before saving and deploying.
-
For major schema changes, use Unlock Schema and document the rationale and mapping.
-
Test changes in a staging environment, then roll out gradually.
Troubleshooting
-
Missing PK/keys: Define logical keys to ensure updates and deletes work correctly (Logical Keys).
-
Type errors: Implement parsing in a UDF and/or adjust the target type via Unlock Schema.
-
Unexpected nulls: Confirm UDF logic sets required fields and handles edge cases.
-
Target not found: Pick a different target schema/table or verify connectivity and permissions.
Here following an example of how erros are displayed: