Gluesync - RDBMS and NoSQL data replication
Gluesync is a software product for real-time event-based data replication from RDBMS to NoSQL databases and viceversa, plus NoSQL to NoSQL databases too. This means that you will be able to replicate data to and from relational, non-relational and between non-relational databases in real-time using native technologies officially supported and maintained by each database vendor, deployable in any cloud, virtual or containeraized environment and on-prem deployments, even on bare-metal servers.
You can read more about Gluesync’s native approach looking at our blog article The Gluesync Journey.
In this documentation you can find the installation and configuration steps necessary to setup Gluesync into your infrastructure and connect a RDBMS instance with a NoSQL database. But, before jumping into the details, let’s talk about few core concepts.
Core concept behind Gluesync’s architecture
One of the main considerations we took when designing the Gluesync architecture is its native ability to be upscaled and deployed with ease, just like you used to do with your container-based applications: pull-config-deploy-enjoy. That’s the motto. You gain full control of what happens under the hood without keeping you into playing with GUIs that wouldn’t have allowed you to harness the full potential of this data replication suite.
Gluesync is being shipped through docker containers, if you haven’t already read about docker containers you can have a look here at this link that points you directly to the official docker’s homepage.
This doesn’t mean that if you don’t have the possibility to run a docker environment into your infrastructure you couldn’t run Gluesync, on the contrary! You can ask our team to provide you the package for your specific destination platform in order to run it even on-prem in bare metal servers.
Here in the following diagram is represented an architectural overview of a Gluesync environment.
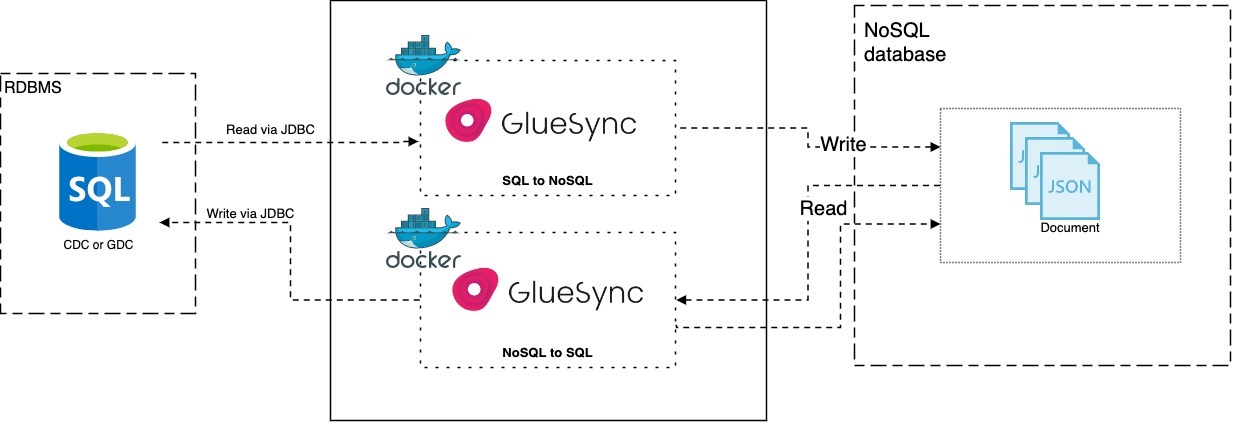
Design
The design concept that have been adopted has basically been taking in consideration the purpose of each core functionality provided by the suite: it provides ability to replicate data from a relational database to a non-relational database and viceversa. This two aformentioned functionalities are called "ways" or "directions".
So, rather than having a monolithic single piece of general-purpose software, we have decoupled its functinalities into an auto-consistent and highly-resilient and specialized service per each "direction". Capable of replicating, logging, alerting and being monitored by itself without the need of a master central authority that could only have increased complexity and introduced a single point of failure into the overall architecture.
Being that said the result and outcome for our users is the ability to decide what to deploy per each use case: you have the control over the decision to deploy only the module to replicate data from MS SQL Server to MongoDB or just the viceversa due to your specific use case. In that way you’re going to have the fine graned control over permissions, security and performances that you deserve from a product made for real-worlds production use cases.
Understanding CDC vs GDC
When talking about sourcing changes from a relational database there are just a few ways to accomplish the task of auditing writes, updates and deletions performed at field-row level. The most common approach, but also the most challenging, is reading from the database transaction logs that luckily nowadays are wrapped around an API layer called CDC - Change Data Capture - which provides a way for application developers and DBAs to read throught it and understand the entire history of the changes that have been made from a certain time frame.
We used the term "challenging" because every database vendor have implemented its way to expose these logs and building a tool capable of being compatible with all of them it is indeed a challenge by itself and sometimes specific vendors or database versions (esperially older ones) don’t provide either CDC or low level APIs to grab transaction logs from it.
In older to provide a wider compatibility on capturing real-time change streams from the vast majority of relational databases out there in the field we decided to develop a fine-tuned subset of UDFs (user-defined functions) that together with a set of triggers helps Gluesync to enlarge the compatibility base with relational databases while maintaining a safe, fast and secure approach with which entire lifecycle is entirely managed by its engine itself. We called this feature GDC - Gluesync Data Capture - used for certain kind of database brands | versions | editions that do not currently (or at all) the native CDC technique or for those who we initially decided to make compatible first throught that feature and then to provide CDC out-of-the-box in the upcoming future.
Naming conventions
As naming conventions to nickname each type of Gluesync "direction" we adopted the following nomenclature:
-
replication from relational (RDBMS) to non-relational databases (NoSQL) has been labeled "SQL to NoSQL"
-
replication from non-relational (NoSQL) to relational databases (RDBMS) has been labeled "NoSQL to SQL"
What you’re going to need
Before proceeding, for each Gluesync instance that you’re willing to deploy, please check if you have the following information:
-
RDBMS connection details, like:
-
Username
-
Password
-
Connection string (IP address / port)
-
Tables names
-
-
NoSQL database connection details, like:
-
Destination, either bucket or database
-
Connection string (IP address / port)
-
Username
-
Password
-
If you’re involved on the implementation of Gluesync or just tryng it out via our trial program, we higly suggest you to have a visual query editor tool in order to bootstrap multiple datasources connection, easily import / edit / display data. The tested tools from the Gluesync product and QA teams are:
As MOLO17 we do not provide any support on these specific tools neither we advertise them, you are free to use the toolset that you prefer the most in order to connect and perform queries against your database(s).
Compatibility matrix
Non-relational databases (NoSQL)
| vendor / edition / version | Gluesync compatibility | Technology used |
|---|---|---|
Aerospike |
✅ from Gluesync v1.3.4 starting from version 5.X and above all editions |
write-to performed through official SDK, ability to read CDC stream planned for Q1 2023 |
Azure CosmosDB |
⏱ support coming soon |
- |
Cassandra |
⏱ support coming soon |
- |
Couchbase |
✅ from Gluesync v1.0 starting from version 5.5 and above all editions |
Native CDC via Eventing service, writes performed through official SDK |
CouchDB |
⏱ support coming soon |
- |
DynamoDB |
⏱ support coming by Q4 2022 |
- |
MongoDB |
✅ from Gluesync v1.3 starting from version 3.6 and above all editions |
Native CDC via Change Streams, writes performed through official SDK |
RavenDB |
⏱ support coming soon |
- |
Redis |
⏱ support coming by Q4 2022 |
- |
BigData store
| vendor / edition / version | Gluesync compatibility | Technology used |
|---|---|---|
Amazon AWS S3 |
✅ from Gluesync v1.3.4 |
write-to performed through official SDK, read comming soon |
Apache HBase |
⏱ read support coming by Q4 2022 |
- |
Azure data lake |
⏱ write-to support coming soon |
writes will be performed through official SDK |
Databriks |
⏱ write-to support coming soon |
writes will be performed through official SDK |
Google Cloud Storage |
⏱ write-to support coming soon |
writes will be performed through official SDK |
Snowflake |
⏱ write-to support coming soon |
writes will be performed through official SDK |
Relational databases (RDBMS)
| vendor / edition / version | Gluesync compatibility | Technology used |
|---|---|---|
DB2 for series i (AS/400) and DB2 for z/OS |
writing (as a target) is fully supported, ⏱ CDC support coming by Q4 2022 |
writes performed with native JDBC drivers |
MariaDB |
✅ from Gluesync v1.3.3, tested from version 10.0 and above |
Via Gluesync Data Capture (GDC) |
Microsoft SQL Server and Microsoft SQL Azure |
✅ from Gluesync v1.0, all editions |
Native CDC via Change Tracking, from version 2016 and via Gluesync Data Capture (GDC) older versions |
MySQL |
✅ from Gluesync v1.3.3, tested from version 8.0 and above |
Via Gluesync Data Capture (GDC) |
Oracle Database and OracleDB on OCI |
✅ from Gluesync v1.2, all editions |
Native CDC via Xstream APIs from 11.2g and via Gluesync Data Capture (GDC) older versions |
PostgreSQL |
✅ from Gluesync v1.3.3, tested from version 9.0 and above |
Via Gluesync Data Capture (GDC) |
SAP Hana |
⏱ CDC support coming soon |
- |
SingleStore |
⏱ write-to support planned, CDC support coming soon |
- |
Sybase SQL (Adaptive Server Enterprise, ASE, SAP Sybase) |
✅ from Gluesync v1.3.3, tested from version ASE 15.7 and above |
Via Gluesync Data Capture (GDC) |
Sybase SQL Anywhere |
✅ from Gluesync v1.3.3, to be tested |
Via Gluesync Data Capture (GDC) |
YugabyteDB |
⏱ CDC support coming soon |
- |
| Tested means that actually each version that ranges from the specific tag mentioned and above are currently under the integration tests suite and being tested together with performance benchmarks that are performed per each commit-basis in order to ensure no regression and the best quality outcomes. Other versions older that those included in our test suites might work but are not currently battle-tested for a production use case. If you would like to consider testing a specific database version which appears to not have been currently made compatible you are more then welcome to join our beta program, in that case consider to drop us a line at this email address telling us that you would like to be part of the beta program for a specific db version tag. |