What’s New in Gluesync 2.0: Major Features & Updates
A massive new release: 2.0 marks our biggest release to date.
🌶️ Hot topics 🌶️
Every major release comes with a huge list of changes. Release 2 for us is huge, with over 12 months in the works we rewrite every corner of what you knew about Gluesync starting from the way you were used to setting it up.
This release makes everything so new that even for the veterans of our community we’re sure they will feel like this is an entirely new software. Did I say software? That’s a habit I have to forget… what I meant is Platform. Gluesync release 2 can’t any longer just be called software or referred to as a tool. What we are now bringing you is a platform, thought from the ground up to serve hybrid data workloads: from on-prem to cloud, from RDBMS to NoSQL, from columns and rows to destructured, complex and new data models.
The list is very long, so… buckle up and let’s start!
Psst, we have a video here you might like to take a look at: it’s our Gluesync 2 release party event!
A whole new architecture
A future-proof architecture: we’re paving the way for what’s next. Release 2 is the foundation to begin building what we have in our roadmap: I can’t tell you more at the moment… but expect many things beyond just data replication.
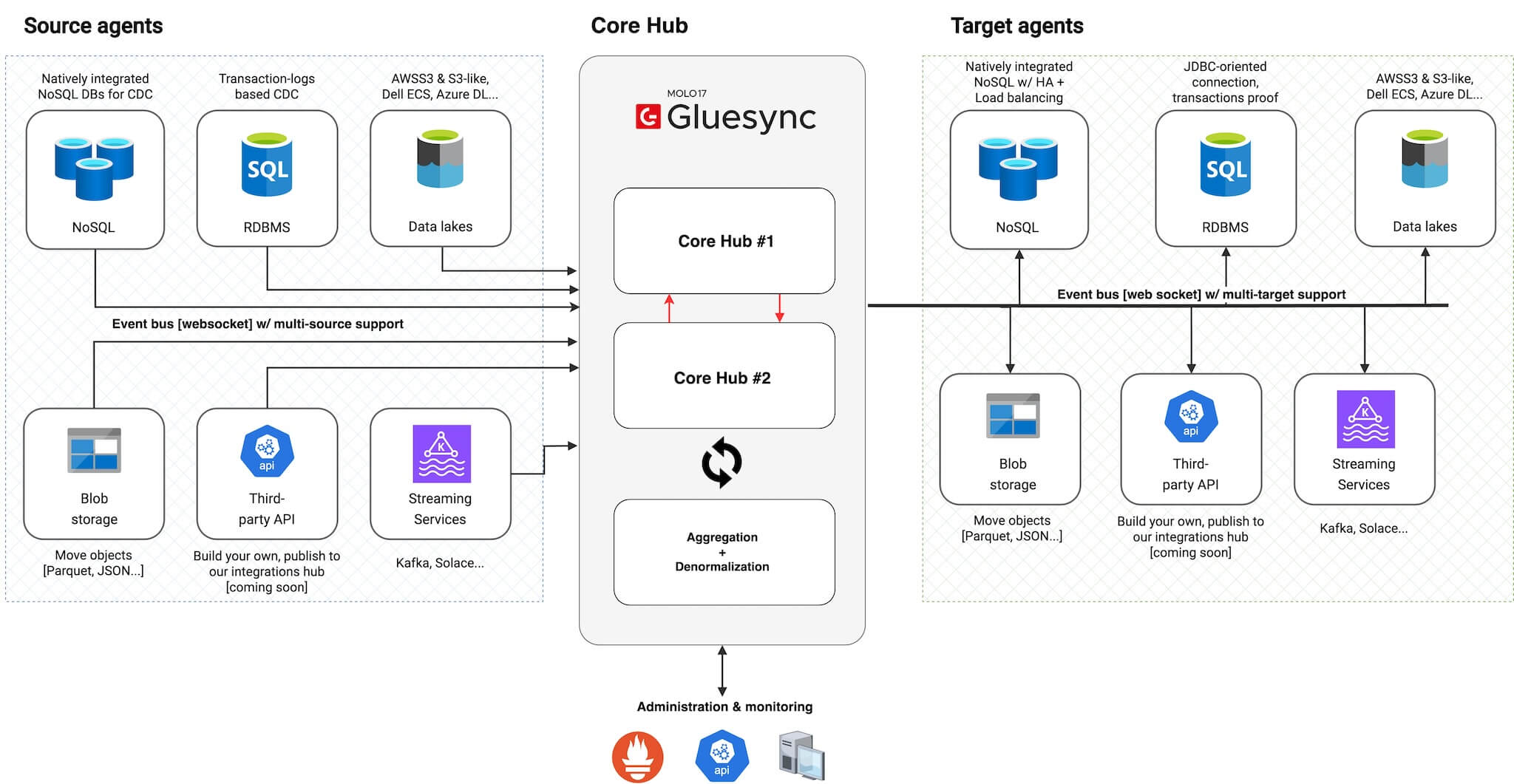
Just this chapter deserves 100 pages by itself: you see the above new components that weren’t present in Gluesync before, like Agents, Core Hubs and APIs to name a few.
We suggest you read our newest intro to Gluesync made for both new & veteran users.
Leaving the stateless, embracing the stateful
If you’re familiar with Gluesyc 1.X you might know that it was originally designed to be stateless: it was previously storing checkpoint data & additional metadata within the source database, leveraging its underlining backup infrastructure and data structure.
A decision to shift away from a stateless architecture has been discussed a lot at both the engineering team level as well as the product management level: we then decided to provide Gluesync 2 with stateful capabilities for many reasons, some are briefly summarized here:
-
Change agility: making changes to data structure among versions is always hard, and is even harder if you’re storing data in a production database that you do not own.
-
Gain control within the platform: it’s hard to make decisions if metadata are stored elsewhere, permissions can change out of your control, data can be altered without a way for you to trace back what happened;
-
Autonomy: we believe a platform should have its independence from other components/parts of the infrastructure to provide resilience and reach a set of enterprise features (especially security & safety measures).
Core Hub: the platform 🧠
A platform requires a component in charge of all the most critical tasks: in Gluesync 2 we have the Core Hub, the central brain of the entire platform.
Core hub’s main language is API and web sockets: every detail has been carefully crafted to enrich our users' experience while using Gluesync to connect data from as many different data sources as the platform permits.
Want to read more about the Core Hub? Take a look at our primer about it.
APIs
You read it correctly: now Gluesync comes with APIs, not just for monitoring as we were used under 1.X, but now these APIs are for admin operations as well.
JSON Rest APIs are made for developers that this time can directly administer even the most complex tasks via a Rest client interface or augment what the platform currently provides in terms of features like, for example, scheduling tasks.
APIs are available starting from this link.
Meet the Control plane
The control plane is where you control, set up, administer, monitor & track the data flow across your pipelines. Like every control plane that deserves respect, it is the underlying control room of the platform where you can control and orchestrate operations.
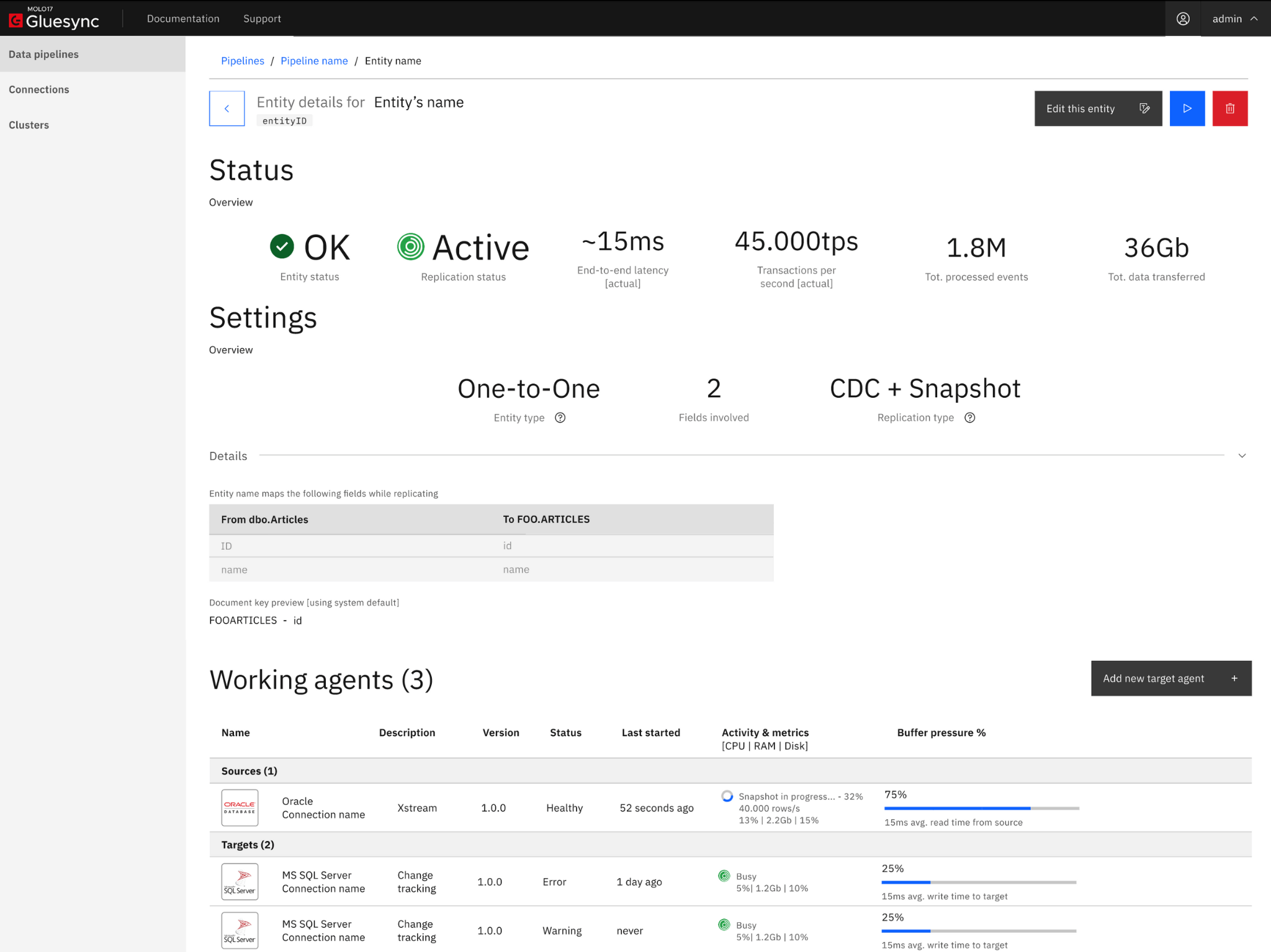
This powerful UI is our commitment to providing a super-smooth and easy-as-possible way for our growing community of users to configure and define data pipelines within the Gluesync data integration platform.
More about it here: Control plane deep dive.
RDBMS ←→ RDBMS 🥂
You read it right: replication tasks between RDBMSs are now possible. Gluesync 2 takes care of everything for you, whether the task involves a homogeneous or a heterogeneous replication.
You can now replicate between Oracle to PostgreSQL, from Sybase to MS SQL Server or from IBM DB2 to Snowflake, just to give you some examples.
New integrations 🔌
Not only did we work a lot under the hood but also we made tangible improvements & tons of new functionalities you will discover & love along the way, starting from some of the new integrations that have been added to celebrate the 2.0 release!
While previously the engineering team was constrained on releasing new integrations due to the past software architecture, with Release 2 there are no more physical constraints: this means that the team can focus on developing new integrations at the speed of light without compromising the quality.
Quality deserves a chapter on its own… let me disclose that we invested and investing a lot on the topic with a battery of servers performing automated integration tests carefully written by our team. These tests automatically launch the needed databases, load them with the test suite data, configure the database for the CDC, deploy Gluesync, configure Gluesync and then run a heavy number of queries/operations to stress test Snapshot and CDC features to check for regressions and to validate functionalities.
The integration tests suite alone is another piece of IP!
MySQL & MariaDB
Previously available only with support based on Triggers auditing structure, we made a step forward and in 2.0 you now have two new agents that are capable of reading directly from MySQL & MariaDB transaction logs using the bin logs.
Expect so incredible performances and broader and native support for much more versions of MySQL and MariaDB in all of their flavors.
ClickHouse
ClickHouse can now be used as a target from any available source agent.
SingleStore
SingleStore can now be used as a target from any available source agent.
Snowflake
Snowflake can now be used as a target from any available source agent.
Vertica
Vertica can now be used as a target from any available source agent.
Data modeling & more
Data modeling is currently under heavy refactoring and will be made available back within the platform during the next few iterations. Expect a big leap forward in terms of performance improvements, especially in terms of resource footprint at the source database level.
HA features
Core Hub in 2.0 supports a single-node mode since we know that many of you care a lot about HA (high availability features) we’re close to releasing one of four features we have considered including in terms of HA. Let me provide you with a summary of our roadmap for such functionality:
-
Primary/secondary architecture: a primary Core Hub node is elected to serve clients' requests while the secondary remains available and consistent to serve as a primary in case of failure;
-
Active-active pattern: two or many Core Hub nodes work together and share loads at the pipeline level. Whoever goes down the other(s) are capable of recovering;
-
Multi-cluster active DR: different Gluesync’s can be deployed within different VPCs / data centers to provide disaster recovery capabilities. This feature is meant to be proactive: meaning that each Gluesync deployment will have the ability to actively take over the one from a failed data center.
-
Active-active with intelligent load balancing: two or many Core Hub nodes work together and share loads at the entity level. Whoever goes down the other(s) are capable of recovering;