Gluesync’s stateless principles
Understanding where data is kept
Due to its stateless nature Gluesync doesn’t store data within any internal datastore, making instead use of data source and target databases for that task. To maintain its state, it makes use of the persistent storage layers it is connected to. In that way at every single restart, it is capable of recovering from its last known state just by reading from either the source repository or the target one, depending on the use case.
DBA can find these tables inside the Gluesync schema given when issuing its user credentials.
State preservation table
This is the most important table for Gluesync, it plays the role of keeping its persistent status consistent per each of the audited source entities (tables, collections, schemas…).
The definition of this table structure is described here following. No relevant/sensible data is stored there inside this table.
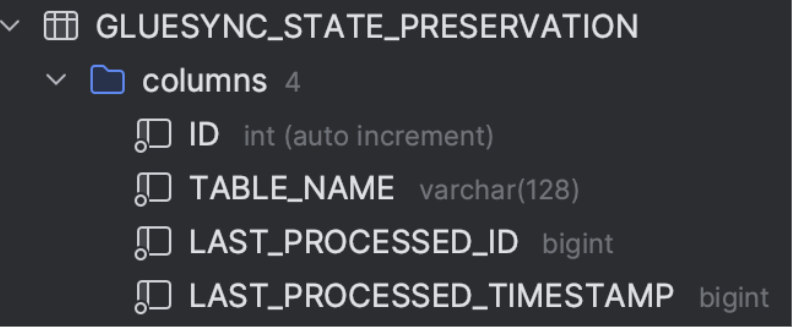
This table is under both Gluesync and DBA control. Can be used to reset Gluesync status by removing either row entries or truncating/dropping the entire table. Gluesync will try re-creating the same at the next run.
Migration checkpoint table
This table contains the status of the initial table migrations checkpoints Gluesync creates to keep track of the internal progress of initial data loads performed at user request after having issued table entries in the Gluesync configuration file.
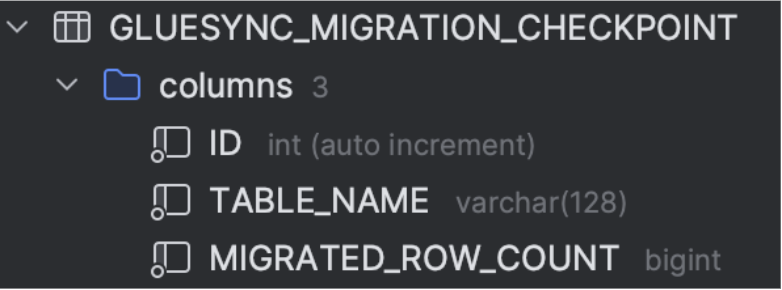
Stored rows count helps Gluesync do a point-in-time recovery if the initial snapshot process is paused or stopped.