Data modelling in Gluesync
Data modelling is an essential toolkit that we provide in order to let developers and DBAs achieve the best out from their destination target database especially when it comes to map and model data in JSON documents accordigly to the application business logics / presentation layer point of view. This means that with that feature you will be able to implement different document design strategies that will result in a boost of performances and productivity at the destination application level.
| The options described below may require additional resources to be processed. We suggest having on board our professional services to fine tune and properly size the containers and number of nodes required to satisfy your production workloads. |
Core principles
It is important to mention that every operation that Gluesync does when modelling your data do not involve data introspection at the Gluesync core modules-level that because of the security design approach that our engineers adopted when crafting the core replicators modules.
Being that said every operation that involves data modelling is performed against the source or destination database engine, leveraging its full set of features and achieving the best out of compatibility from it, talking about SQL language stadards support, performances and data types.
Is on these solid principles that we refer to it with the term on-the-fly data modelling when talking about the Gluesync data modelling capabilities, bacause is indeed designed for in-memory-only computation without the need to store or persist no bit of data either while transfering or applying modelling-related business logics.
Data modelling 101
These are the current supported group of different features that Gluesync offers in terms of data modelling on-the-fly:
-
Field skipping, ability to skip certain fields avoiding its replication;
-
Field renaming, ability to rename fields;
-
SQL queries JSON modelling, apply SQL statements on your datasource to output a tailored JSON document data model;
-
Advanced data modelling: using our meta-description language you can describe how data has to be modeled achieving unparallel customization level with nested JSON support (arrays, objects…) of up to 2 levels deep (even more coming soon…).
Each of these are meant to support you on the journey of replicating data from a relational database to a NoSQL database or viceversa, overcoming challenges like post-commit document manipulation or UDFs (user defined functions) that could slow down the time-to-data need that you might have, making real-time data replication challenging.
| Every data modelling function that Gluesync supports works both while capturing changes through CDC or GDC and also when the initial snapshot of data is performed. This means that you don’t have to handle any manual data modelling task. |
Field skipping
This functionality is available both for SQL-to-NoSQL replication and viceversa following the respective links:
You should use this functionality in order to avoid unwanted fields to being replicated on the counter side, preserving space: don’t forget that each key in a JSON document is repeated per each document in your NoSQL database, meaning that if there are certain colums that you are not considering to use in NoSQL are easily avoidable using that feature in order to save space and resources.
Field Renaming
This functionality is available both for SQL-to-NoSQL replication and viceversa following the respective links:
You should use this functionality in order to rename long column names or just making them more use-case oriented in order to let them being replicated on the counter side with a new name. A common use case is preserving space: don’t forget that each key in a JSON document is repeated per each document in your NoSQL database, meaning that if there are certain colums that have long names you might be considering to rename these in order to save space and resources.
SQL queries JSON modelling

This feature enables you to define a SQL query statement, the same that you are used to use while performing queries against your relational database, in order to aggregate, map and design an output structure that will be then transformed by Gluesync data modelling engine as a JSON document output. It works both while initially moving your entire dataset (tables and columns defined in the statement) and also while performing CDC incremental replication.
To learn more about this functionality please visit the related page at this link: SQL queries JSON modelling.
As for now this functionality is only supported when replicating changes from a relational database to a NoSQL database, more extended support is on our developement roadmap and will be soon made available.
Advanced data modelling
Version v1.4 introduces this feature we called Advanced data modelling since it enables users to highly customize their data modelling output using our easy to learn meta-description language that helps you define how data should be joined, filtered, columes skipped or renamed, all while providing a way to freely define the level of deep you want your data be represented: JSON documents provides you a wide range of possibilities in terms of application data model flexibility, so we do.
Imagine in how many ways you could have decided to output the same query result from the tables structure from the picture here below:
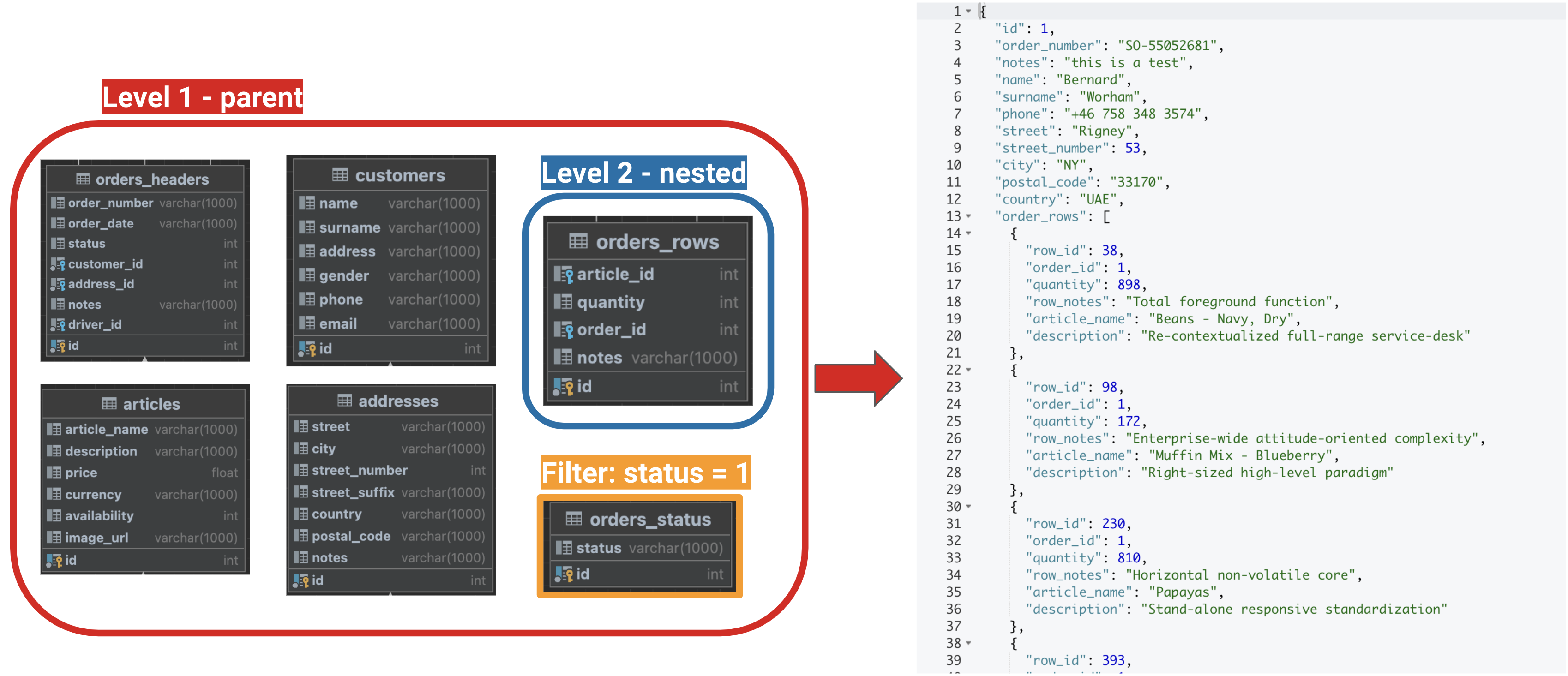
In this e-commerce like use case you could have decided to:
-
nest order rows inside all the relevant customer and order information needed by the delivery person
-
split orders header and rows information on different JSON documents, while keeping customer and shipping address info on the same document as header;
-
split orders header, rows, customer, address information on different JSON documents;
-
…we can continue imagine different scenarions all day long: but what it matters is that you decide based on your specific use case: it’s a trade-off between commodity / performances / flexibility and so on.
Start now with Advanced data modelling sourcing from RDBMS here at this link: Advanced data modelling from RDBMS.
Looking for Advanced data modelling when sourcing from NoSQL databases? Follow this link: Advanced data modelling from NoSQL.